Training latent diffusion models (LDMs) typically requires a lot of compute which slows the iteration cycle for research in the autoencoder stage. To combat this, I wrote a minimal repo for training small scale autoencoders and latent diffusion models (LDMs) on those latent spaces. miniLDM uses the CIFAR10 dataset of 50k 32x32 images to achieve a fast iteration cycle. The training loop also uses torch.compile and half-precision to significantly speed up training.
I could train the VAE in ~1 hour and the LDM in ~17 hours on a single RTX 3060 GPU with a final FID of ~15 using CFG weight 3.0.
Efficiency #
To speed up the development cycle, I tried adding efficiency optimizations to the training loop with the following results for the AutoEncoder stage.
| Optimization | Iters/sec | Speedup over baseline |
|---|---|---|
| Baseline | 2.13 | - |
| +mixed precision | 2.85 | 1.3x |
| +torch.compile | 4.76 | 2.2x |
At the batch size tested (256), the memory utilization was a fraction of the total VRAM available but increasing batch size did not bring further speed ups in terms of throughput (images processed per second). This is likely because we are hitting the memory bandwidth constraints of data transfers from HBM to on chip memory, these small scale models are unlikely to be compute bound.
AutoEncoder #
I used a small 3.5M parameter version of the FLUX.1 UNet architecture for the autoencoder. I trained for ~100k iterations using AdamW at batch size 32. I tried various patch sizes and latent channels to observe the effect on reconstruction accuracy. I tried 8x8 and 4x4 latent spaces with 8 and 16 channels. As expected, the larger the latent space and the higher the number of channels, the lower the reconstruction loss.
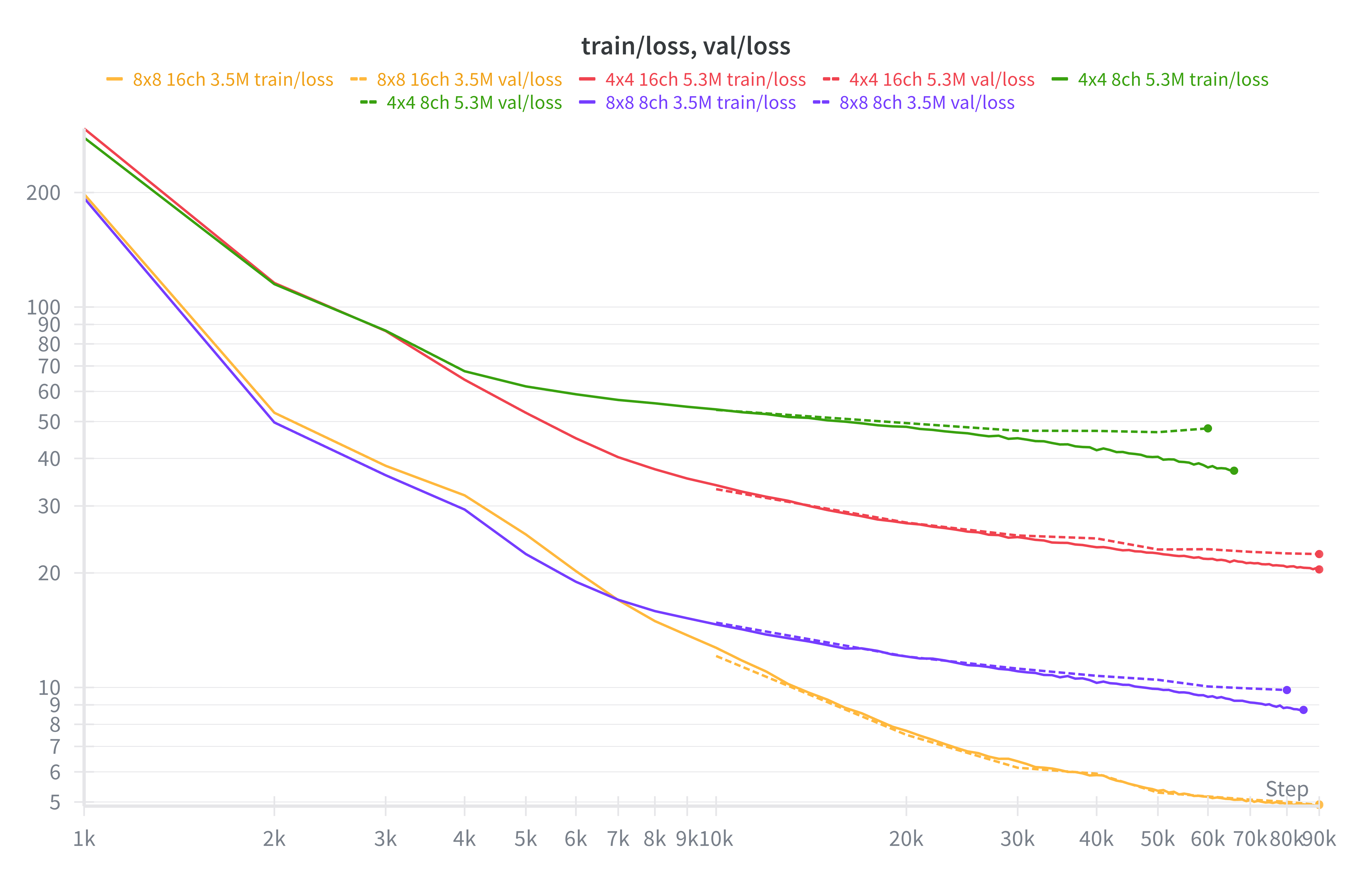
Examining the reconstructions, I decided that I needed to use the 8x8 16ch autoencoder to have any reasonable looking images since the autoencoder reconstruction quality will set an upper bound on the image quality we can expect from the generative model.
LDM #
I then trained a latent diffusion model on the latent encodings of the CIFAR10 training set (50k images). I used a 30M parameter Diffusion Transformer architecture for the LDM. I trained for ~800k iterations with AdamW and batch size 128. The architecture is class conditional with stochastic dropout of the label encoding to enable classifier-free guidance (CFG).
The model overfits quite quickly, with validation loss increasing after around iteration ~200k however FID continues to decrease to a minimum at ~650k. This is an interesting phenomenon in generative models whereby the validation diffusion loss does not always give the full picture in terms of raw sample quality.
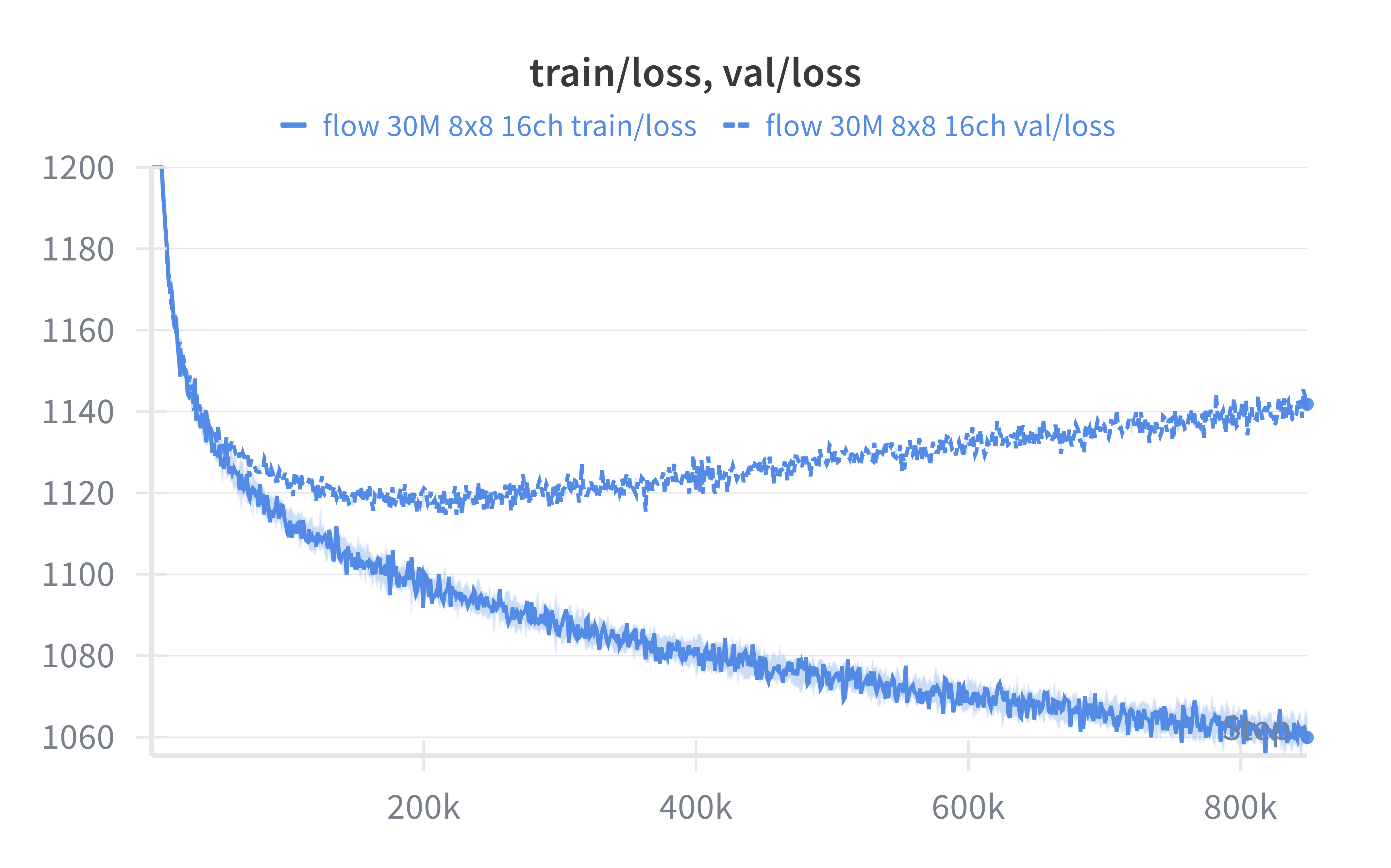
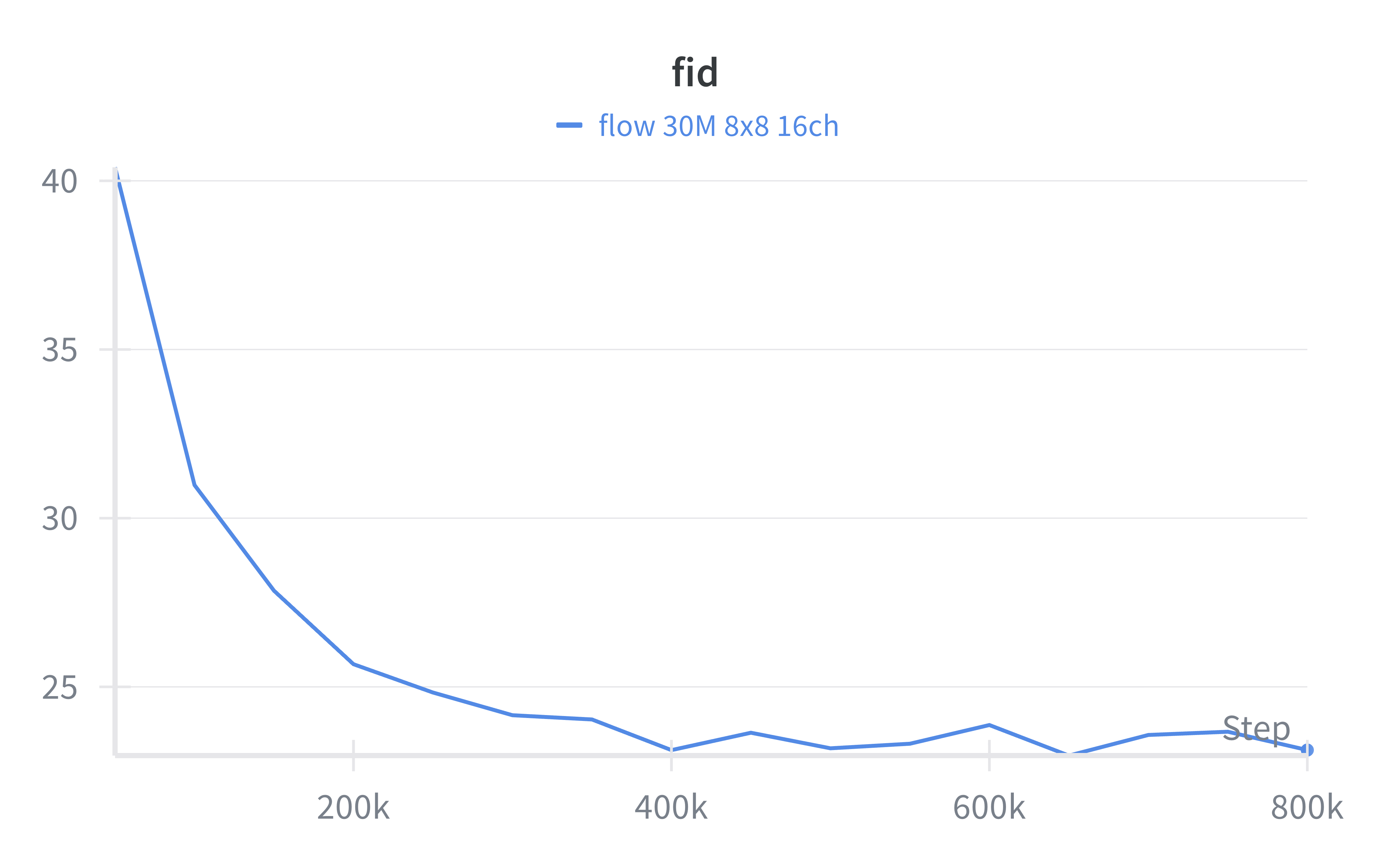
It took 5 hours to reach minimum validation loss at 200k iterations and 17 hours to reach minimum FID at ~650k iterations.
Samples #
I sampled the 650k checkpoint and found increasing the CFG weight to 3.0 resulted in the best sample quality with an FID of 15.5 with 128 sampling steps of an Euler solver for the probability flow ODE.
Here I show 100 samples using 50 steps and CFG 3.0 (FID 15.9).

Discussion #
The sample quality could definitely be improved, it will be interesting further research to use techniques that can regularize the training of the autoencoder so that it can have high reconstruction quality whilst also being amenable to learning a diffusion model in its latent space. Naively increasing the number of channels to improve reconstruction quality results in a poorly conditioned frequency spectrum of the latent space that does not play well with a diffusion models natural generation ordering of low frequency to high frequency (also known as spectral autoregression).
It would be interesting to apply techniques from recent papers investigating frequency regularization: Improving the Diffusability of Autoencoders and Delving into Latent Spectral Biasing of Video VAEs for Superior Diffusability.